随着数字化突飞猛进,科技对人类的重要性从未如此之高,前所未有地塑造着未来的世界。如此迅速的数字化进程带来了数据量的爆炸式增长和数据类型的多样化,也因此提出了不断增长的算力需求。如果说“算力”是数字世界的生产力,半导体则是数字化的支撑性技术。因而,推进半导体行业的技术创新就显得尤为重要。
近日,英特尔总结了2022年公司在技术创新和产品发布上的最新进展,英特尔公司高级副总裁、英特尔中国区董事长王锐表示:“创新是英特尔安身立命之本。在2022年,面对宏观经济环境和半导体行业调整周期带来的诸多挑战,英特尔放眼未来,迎难而上,基于对数字化趋势的深刻理解,坚持一步一个脚印地推进技术创新。在制程、封装等领域实现了底层技术突破;在软硬件产品方面继续推陈出新;不断提高英特尔在代工服务方面的执行力。”

2月
从开幕式上基于英特尔®至强®可扩展处理器的3DAT技术,到应用于不同场馆和赛场的AI数据分析、360° VR技术平台、VSS数字孪生场馆模拟仿真系统等等,英特尔创新技术“闪耀”北京冬奥会。

英特尔公布代工领域的一系列动作:
以54亿美元收购领先的半导体解决方案代工厂Tower半导体,此收购大力推进了英特尔的IDM2.0战略,进一步扩大了英特尔的制造产能、全球布局及技术组合

推出一项10亿美元创新基金,用于扶持早期阶段的初创公司和成熟公司
加入RISC-V国际基金会,推动建立开放的代工生态系统

在英特尔2022投资者大会上,英特尔分享了产品和制程工艺技术路线图及重要节点:
在制程方面,英特尔将通过极紫外光刻(EUV)技术、RibbonFET晶体管和PowerVia背面供电技术,在四年内推进五个制程节点,预计将在2025年重获制程领先性

在封装方面,下一代3D封装技术Foveros Omni和Foveros Direct预计将在2023年正式投产
3月
英特尔携手行业领先企业成立UCIe(通用芯粒高速互连开放规范)联盟,推动建立开放的芯粒生态系统,让不同供应商用不同制程技术设计和生产的芯粒能够通过先进封装技术集成在一起并共同运作。

英特尔推出面向笔记本电脑的英特尔锐炫™独立显卡系列,旨在为全球游戏玩家和内容创作者带来高性能的图形体验。

4月
英特尔宣布计划进一步减少直接和间接温室气体排放,承诺到2040年全面实现“可持续计算”,实现全球业务的温室气体零排放。

英特尔与QuTech研究员首次在300毫米的硅晶圆上实现了硅量子比特的规模化生产,实现了量子比特数量与良率的突破。

5月
在英特尔On产业创新峰会上,英特尔公布了在芯片、软件和服务方面取得的多项进展,为客户释放商业价值:
芯片
用于训练数据中心负载的英特尔Habana® Gaudi® 2 AI处理器

代号为Sapphire Rapids的第四代英特尔®至强®可扩展处理器的初始SKU
英特尔基础设施处理器(IPU)的路线图

软件
英特尔软件基础设施计划Endgame项目,帮助用户随时随地灵活调用计算资源
服务
Intel® On Demand服务,满足企业不断变化的工作负载需求,实现产品可持续发展
6月
英特尔研究院宣布在集成光电研究上取得重大进展,实现了完全集成在硅晶圆上的八波长分布式反馈激光器阵列,输出功率和波长间隔均匀性均优于行业规范,且具备未来大规模应用所需的性能。

7月
英特尔正式推出了首套开源AI参考套件,旨在让企业能够在医疗、制造、零售和其他行业部署准确性更高、性能更优和总落地成本更低的AI。
英特尔与全球领先的无晶圆厂芯片设计公司联发科宣布建立代工合作关系,联发科将使用英特尔的制程技术为一系列智能边缘设备生产多种芯片。


8月
在第34届Hot Chips大会上,英特尔CEO帕特·基辛格介绍了英特尔在架构和封装领域的最新创新成果,这些成果增强了分块化2.5D和3D芯片设计,将被应用于英特尔即将推出的产品组合。
9月
在英特尔On技术创新峰会上,英特尔展示了一系列全新软硬件产品和服务,以及在构建开放生态系统方面的最新进展,旨在帮助其庞大的开发者生态系统应对挑战并实现新一代的创新:
产品和技术组合
以旗舰产品英特尔®酷睿™ i9- 13900K为首的第13代英特尔酷睿台式机处理器,带来了台式机处理器性能的新标准

英特尔数据中心GPU Flex系列,为客户提供了基于单一GPU来满足广泛智能视觉云工作负载需求的解决方案

面向台式机的英特尔锐炫™ A7系列显卡,以多种产品设计登陆零售市场,提供出色的内容创作和游戏性能

英特尔多设备协同技术(Intel® Unison™)可在手机和电脑之间提供无缝连接
第四代英特尔®至强®可扩展处理器内置一系列加速器,主要用于人工智能、数据分析、网络、存储和其他高需求的工作负载
支持工具
全新英特尔® Geti™平台能够助力企业快速、轻松地开发和部署计算机视觉AI

英特尔研究院发布基于Loihi 2研究芯片的可堆叠多板平台Kapoho Point,并更新Lava开源软件开发框架,推进神经拟态计算的应用开发

新的英特尔量子软件工具包旨在帮助开发者学习如何编写量子算法
英特尔再次发布三套专门针对医疗健康用例的全新AI参考套件
10月
英特尔介绍,英特尔代工服务将通过“系统级代工”为客户提供晶圆制造、封装、芯粒和软件四个领域的服务,开创芯片制造的新时代。

11月
在2022年世界互联网大会乌镇峰会上,英特尔CEO帕特·基辛格表示,五大“超级技术力量”,包括无所不在的计算、无处不在的连接、从云到边缘的基础设施、人工智能、传感和感知,将在芯片的驱动下于数字时代释放出更强大的全新可能。同时,他也强调,英特尔将延续和中国的长期合作伙伴关系,通过超级技术力量创造可以造福社会的科技。

12月
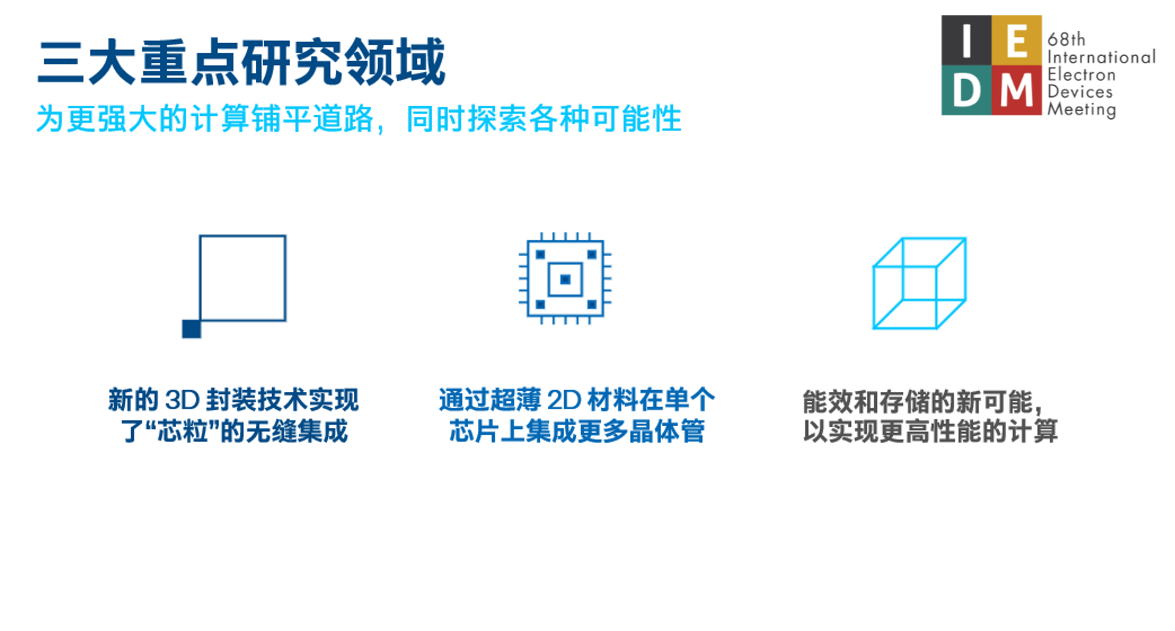
在IEDM 2022上,英特尔公布了多项研究成果,继续推进摩尔定律,以在2030年前实现在单个封装中集成一万亿个晶体管:
将互联密度再提升10倍的下一代3D封装技术,实现了准单片式芯片
用于2D晶体管进一步微缩的新材料,包括仅三个原子厚的超薄材料
能效和存储的新可能,以实现更高性能的计算
1
英特尔® oneAPI工具包的2023年版本正式上线,可大幅提升即将推出的英特尔硬件产品的性能和生产力,包括第四代英特尔®至强®可扩展处理器、英特尔®至强® CPU Max 系列和英特尔®数据中心GPU,涵盖Flex系列和新的Max系列,并增加了对新的Codeplay插件的支持,使开发者能更容易地为非英特尔的GPU架构编写SYCL代码,从而让面向多架构系统的代码开发变得更轻松。

3
面向未来,英特尔仍将继续坚持“创造改变世界的科技,造福地球上每一个人”的宗旨,在摩尔定律的启迪下推进技术创新,同时不断探索计算的新可能性,以在进一步提高算力的同时降低能耗,助力全人类的可持续发展。
重磅!制程工艺变天,“纳米数字游戏”里的“猫腻”要被终结了
一直以来,制程节点都是衡量工艺演进的重要数字。一串看似无规律的数字,实际上背后隐含的是摩尔定律所划分的晶体管栅极最小线宽。
但摩尔定律每两年翻一番速度之下,早在1997年栅极长度和半截距就不再与这种节点名称匹配。更何况行业已逼近1nm的极限,行业需要更加科学和更加精密的表述形式。
日前,英特尔CEO帕特·基辛格(Pat Gelsinger)重磅宣布公司有史以来最为详细的制程技术路线图,不仅宣布在2024年进入埃米(Ångstrom)时代,还宣布了将以更加科学先进的方式度量制程节点。除此之外,与之相关的突破性架构和技术以及未来的规划逐一被披露。
在制程节点方面,帕特·基辛格宣布将会以每瓦性能作为关键指标来衡量工艺节点的演进,这是因为对于半导体产品来说,PPA(performance,power and area,性能、功耗、面积)是非常重要的指标。
按照目前的进度来说,英特尔在去年架构日正式宣布10nm SuperFin,并在后续新品中使用。展望后续,将会以全新的方式命名。
Intel 10nm SuperFin: 这项技术是在2020年架构日正式宣布的,同年7月在Tiger Lake中使用;后续2021年至强Ice Lake和Agilex FPGA新产品中也已开始使用。
彼时英特尔宣布的SuperFin技术,是一项媲美制程节点转换的技术。SuperFin其实是两种技术的叠加,即Super MIM(Metal-Insulator-Metal)电容器+增强型FinFET晶体。从参数上来看,增强型FinFET拥有M0和M1处关键层0.51倍的密度缩放、单元更小晶体密度更高、通孔电阻降低2倍、最低的两个金属层提高5-10倍电迁移。
Intel 7: 英特尔此前称之为10nm Enhanced SuperFin,即对SuperFin技术继续打磨。Intel 7将会亮相的产品包括2021年面向客户端的Alder Lake以及 2022年第一季度面向数据中心的Sapphire Rapids。
据介绍,通过对FinFET晶体管优化,每瓦性能对比此前发布的10nm SuperFin提升约10% - 15%。优化方面包括更高应变性能、更低电阻的材料、新型高密度蚀刻技术、流线型结构,以及更高的金属堆栈实现布线优化。而在本次宣布中英特尔彻底删除掉“nm”,改为综合PPA评定的每瓦性能。
Intel 4: 英特尔此前称之为Intel 7nm。Intel 4将于2022年下半年投产,2023年出货,产品包括面向客户端的Meteor Lake和面向数据中心的Granite Rapids。
需要注意的是,Intel 4是首个完全采用EUV光刻技术的英特尔FinFET节点,EUV采用高度复杂的透镜和反射镜光学系统,将13.5nm波长的光对焦,从而在硅片上刻印极微小的图样。相较于之前使用波长为193nm的光源(DUV)的技术,这是巨大的进步。与Intel 7相比Intel 4的每瓦性能提高了约20%。
Intel 3: Intel 3继续受益于FinFET技术,Intel 3将于2023年下半年开始生产相关产品。
这是一个比通常的标准全节点改进水平更高的晶体管性能提升。Intel 3将实现更高密度、更高性能的库;提高了内在驱动电流;通过减少通孔电阻,优化了互连金属堆栈;与Intel 4相比,Intel 3在更多工序中增加了EUV的使用。较之Intel 4,Intel 3将在每瓦性能上实现约18%的提升。
Intel 20A: PowerVia和RibbonFET这两项突破性技术正式开启了埃米时代,Intel 20A预计将在2024年推出。所谓Intel 20A中的“A”代指埃米,1埃米Angstrom =10^-10,1纳米=10埃米。
根据介绍,PowerVia是英特尔独有、业界首个背面电能传输网络,它消除晶圆正面的供电布线需求,优化信号布线,同时减少下垂和降低干扰。RibbonFET是英特尔对于GAA晶体管的实现,是公司自2011年率先推出FinFET以来的首个全新晶体管架构,提供更快的晶体管开关速度,同时以更小的占用空间实现与多鳍结构相同的驱动电流。
Intel 18A: 这仅仅是一种前瞻性说法,未来英特尔将会继续提升RibbonFET,Intel 18A是面向2025年及更远的未来的。此时,行业将继续向更小的埃米提升。
需要特别注意的是,英特尔还将会定义、构建和部署下一代High-NA EUV,并有望率先获得业界第一台High-NA EUV光刻机。英特尔正与ASML密切合作,确保这一行业突破性技术取得成功,超越当前一代EUV。
通过观察路线图,实际上Intel制定的发展路线是围绕晶体管结构进行转变的。在步入埃米时代Intel 20A之前,FinFET(Field-effect transistor)工艺仍然拥有极大的优化空间,在步入埃米时代后直接转向GAA(Gate-All-Around)的RibbonFET。此前台积电也曾表示,决定仍让3nm制程维持FinFET架构。
根据公开资料显示,时下先进制程技术方面,使用的均为FinFET(Field-effect transistor)技术,7nm是FinFET的物理极限,但得益于深紫外(DUV)和极紫外(EUV),制程得以突破7nm、5nm。因此,不难看出Intel的想法与行业是一致的,在Intel 4时候完全引入EUV光刻技术,继续让FinFET结构发扬光大。
当然,英特尔的FinFET与行业不同之处在于叠加了Super MIM(Metal-Insulator-Metal)电容器,变为SuperFin技术。该技术由一类新型的“高K”( Hi-K)电介质材料实现,该材料可以堆叠在厚度仅为几埃厚的超薄层中,从而形成重复的“超晶格”结构。 这是一项行业内领先的技术,领先于其他芯片制造商的现有能力。
通过这样的叠加和对FinFET结构的继续优化,可以支撑制程节点转换到等效2nm节点。但FinFET毕竟有极限,在制程到达埃米级别之时,英特尔选择的也是GAA结构。学术界普遍认为GAA是3nm/2nm之后晶体管的路,厂商也有类似GAAFET的发布。
英特尔将自己实现的GAA称之为RibbonFET,这是一种将栅极包裹在源极和漏极的工艺。而从此时开始,Intel也将会引入更高精度的EUV技术,称之为High-NA EUV,帮助实现埃米级别的提升。值得一提的是,High NA EUV光刻机可谓是炙手可热的产品,其目标是将制程推进到1nm以下,而传言中该光刻机成本甚至超过一架飞机,大约3亿美元。
为什么英特尔执意要把数字放到埃米级别?从英特尔CEO的话中我们可以窥探一二,帕特·基辛格说:“摩尔定律仍在持续生效。对于未来十年走向超越‘1nm’节点的创新,英特尔有着一条清晰的路径。我想说,在穷尽元素周期表之前,摩尔定律都不会失效,英特尔将持续利用硅的神奇力量不断推进创新。”
英特尔既是摩尔定律的发源地,也是忠实的执行者。按照摩尔定律原本的划分方式2nm到1nm之间实质上还是拥有很大的发掘空间,而到1nm之后行业也需要一种全新的划分方式来定义制程节点。此前,行业一直在广泛讨论硅极限的1nm之后的世界,英特尔则直接给出答案——埃米。
英特尔将制程节点变为每瓦性能的测量方式实际上也是有过先例的。在笔者看来,这种度量方式更加客观,更能让行业进行客观的性能对比。
另外,笔者认为,这种转变也是为了此前帕特·基辛格宣布的IDM 2.0的推进做准备。IDM 2.0中,英特尔不仅要开放代工业务,也将引入外部代工,以全新的制程节点测量方式能够方便客户进行横向对比。
资料显示,2017年英特尔引入了晶体管每平方毫米以及SRAM单元尺寸作为客观的对比指标,台积电7nm为90 MTr/mm2,而英特尔的10nm为100 MTr/mm2,这也就能解释为什么业界一直传言英特尔的10nm和7nm性能相当。
此前,笔者也曾撰文评论过行业存在的“纳米数字 游戏 ”现象。虽然制程节点在发明之初,代指的还是栅极长度,但其实从1997年开始,栅极长度和半节距与过程节点名称不再相匹配,之后的制程节点实际意义上不再与之相关。
代工厂在晶体管密度增加很少情况下,仍然会为自己制程工艺命名新名,但实际上并没有位于摩尔定律曲线的正确位置。
台积电营销负责人Godfrey Cheng其实曾经也亲口承认,从0.35微米开始,工艺数字代表的就不再是物理尺度,而7nm/N7只是一种行业标准化的属于而已,此后还会有N5等说法。同时,他表示也确实需要寻找一种新的语言来对工艺节点进行描述。
笔者认为,英特尔在率先使用这种度量方式之后,能够有效敦促行业形成标准规范。诚然,英特尔并没有强制要求行业进行统一度量,但英特尔仍然是以开放的态度愿意将这种规则分享于外界,让摩尔定律得以在正确的道路上发展。
当然,不容忽视的是,封装技术正在成为摩尔定律的新拐点。一直以来,英特尔都将制程和封装放在一起,此次也有全新的封装技术被披露。
2.5D封装方面,英特尔宣布下一代Sapphire Rapids服务器 CPU将成为采用EMIB(嵌入式多芯片互连桥接)批量出货的首个英特尔 至强 数据中心产品。根据解释,这是业界首次通过EMIB将两个光罩尺寸的器件连接在一起,最终让器件性能和单片处理器是一样的。另外,英特尔还宣告了下一代EMIB的凸点间距将从55微米缩短至45微米。
3D封装方面,Foveros将会开创下一代Foveros Omni技术以及对Foveros Omni的补充技术Foveros Direct。Foveros Omni之前名为ODI(Omni-Directional Interconnect),Foveros Direct之前名为Hybrid Bonding技术。当然本次宣布并不只是名字的统一,相关技术也将会持续推进。
从技术角度来看,Foveros Omni允许裸片分解,将基于不同晶圆制程节点的多个顶片与多个基片混合搭配,通过高性能3D堆叠技术为裸片到裸片的互连和模块化设计提供了无限制的灵活性。Foveros Direct则实现了向直接铜对铜键合的转变,可以实现低电阻互连,并使得从晶圆制成到封装开始,两者之间的界限不再那么截然。
封装虽然和摩尔定律没有直接关联,但却又影响着摩尔定律的发展。这是因为封装能够减少芯片间的凸点间距,增大凸点密度。整体的密度越大,实际上也代表着单位面积上晶体管数量越密。英特尔一直洞察到这种关系,所以在此前宣布的六大支柱中是“制程&封装”这种合并的关系。
除了技术上的宣发,英特尔宣布了两个重磅的合作消息:AWS将成为首个采用英特尔代工服务(IFS)先进封装解决方案的客户,高通将成为采用Intel 20A先进制程工艺的客户。
远望未来,制程和封装技术将继续飞扬。在穷尽元素周期表之前,摩尔定律都不会失效, 探索 之路依然长路漫漫。
Intel 12代酷睿详解:内存频率惊人,架构面向未来
日前,英特尔方面召开2021年度“架构日”活动,一口气公布了多达11项的新产品和新技术。但在当时我们注意到,大多数 科技 媒体都将重点放在了刚刚公布的英特尔ARC(中文名:锐炫)独立显卡上,而对于同台亮相的第12代酷睿Alder Lake处理器的架构信息,却鲜少进行解析。
既然如此,以我们三易生活的风格,当然就要选择“吃螃蟹”,来尝试解析一下英特尔此次公布关于12代酷睿的诸多细节。而事实上,当我们仔细研究了英特尔给出的资料后也发现,英特尔这一次的新架构里,信息量真的很大。
“大小核”正式上位,硬件线程调度器为Win11优化
12代酷睿的产品代号为Alder Lake,其最大的特征就是x86处理器史上首次大规模引入了“大小核”设计。请注意,在这里我们说的是大规模引入,因为此前其实英特尔就已经在10代酷睿产品线里,推出过一款带有“试水”性质的大小核处理器酷睿i5-L16G7。
LakeFiled,英特尔首款“大小核”处理器的代号
当然,以结果来说,酷睿i5-L16G7这款处理器无论市场表现还是用户口碑,都称不上出色。而这很大程度上与它只有“1大核4小核”的配置,以及当时Tremont架构(和现在的赛扬N5095、N6210同架构)小核心不太够用的性能和过低的频率有关。
或许是从酷睿i5-L16G7上吸取了教训,在12代酷睿上,英特尔一方面对大核和小核的架构都进行了重新设计,大幅提高了“能效核心(也就是小核)”的效能;另一方面通过自家的“Intel 7”半导体制程,优化了每一种核心的主频。与初代“大小核”处理器酷睿i5-L16G7相比,12代酷睿目前已知的大核心主频从3GHz提升到了5.3GHz,小核心主频更是从1.8GHz提升到了3.9GHz,所以光是频率所带来的单核性能受益显然就将不容小觑。
当然,最为重要的是,与初代“大小核”相比,12代酷睿此次还大幅增加了核心数量。根据目前已知的信息,12代酷睿的“大小核”配置组合基本如下表所示。
可以看到,除了最低端、功耗等级只有5瓦的超低压型号外,英特尔这一次都大幅增加了“大小核”组合中大核心和小核心的数量。特别是在移动端,几乎清一色都有8个小核心,所以其理论上的多任务性能比现在的4核心低压移动版酷睿,是会强上不少的。
这也就意味着对于12代的酷睿来说,其绝大多数型号(包括移动端和桌面端)都会有超过10个以上的物理核心,同时还是两种不同架构并行运作。那么,这就当然需要进行专门的核心调度优化了。所以英特尔与微软合作,在12代酷睿里集成了一个名为“Intel Thread Director(暂译为英特尔线程导向器)”的硬件单元,并确保Windows 11系统对其提供了原生的兼容性。
根据外媒Anandtech从英特尔方面了解到的信息显示,12代酷睿内部的核心优先级,依次为大核心 小核心 大核心的超线程逻辑核心。而Windows 11系统则会根据当前的功耗和任务繁重情况,自动分派任务给不同级别的核心。
举例而言,当用户在台式机或插电运行的 游戏 本上打 游戏 时,系统就会将重要的任务( 游戏 )优先派给大核心执行,不重要的任务(比如后台杀毒)则交给小核心。而如果笔记本电脑处于低功耗运行的状态下,则轻负载任务启动时,可能会被优先交给小核心,以达到节约电量的目的,此时大核心甚至可以被关闭,就像当下的智能手机上那样。
PCIE5.0、DDR5首发,12800MHz的内存你怕不怕
说完了12代酷睿的多核心设计,接下来我们谈谈它此次在I/O部分的一些变化。之所以不急着深入解析架构,主要是我们认为I/O部分对于消费者的影响可能还要更大一些。
首先,英特尔此次的确是对12代酷睿的I/O性能进行了极大幅度的升级。一方面,其CPU内部直接集成了16条全新的PCIE 5.0通道+4条PCIE 4.0通道;另一方面,与之搭配的芯片组(Z690)也将提供12条PCIE 4.0和16条PCIE 3.0。
很显然,英特尔是想要消费者用x16带宽的PCIE 5.0去安装显卡,直连CPU的x4带宽PCIE 4.0用于安装主SSD。但从目前的行业状况来看,PCIE 5.0显卡或许不会那么早推出,但是采用PCIE 5.0 x4接口,读写速度接近1.5GB/s的顶级SSD却有可能即将面世。
因此在实际的PC平台上,主板厂商很有可能会将12代酷睿的PCIE 5.0带宽分成两部分,一半PCIE 5.0x8的带宽用于连接显卡(正好相当于PCIE4.0 x16),另一半PCIE 5.0x8则分解成四条PCIE 4.0x4,可用于实现板载双万兆网卡、多个直连CPU的PCIE4.0 M2插槽,或是其他高带宽接口(例如U2、U3、EDSFF等企业级的SSD接口)等等。
其次,在内存子系统上,12代酷睿也成为了消费级平台中第一款支持DDR5内存的平台。根据英特尔方面公布的数据显示,DDR5内存的起始频率为4800MHz,也就是比现在主流的3200MHz DDR4内存快了50%左右。
可能有的朋友看到这里会觉得有些疑惑,明明现在DDR4的高频内存都已经出到DDR4-5400MHz甚至更高了,DDR5起步才4800MHz,性能岂不是在倒退?
别急,英特尔考虑到了这一点。因为在他们所公布的官方信息中声称,12代酷睿的内存带宽可以高达204GB/s。这句话的信息量其实超大,因为大家要知道,这已经相当于顶级的锐龙线程撕裂者PRO平台配备八通道DDR4-3200内存时的带宽了。仅凭12代酷睿的双通道内存控制器,配合DDR5-4800内存是绝对到不了这么高的。
和DDR4时代相比,超高频DDR5内存这次可能会登场得很早
因此可能性就只有一个了,那就是英特尔方面相当于是在明示,已经有内存厂商准备好了等效频率高达12800MHz的DDR5内存,而且它可以兼容12代酷睿,在这个频率下,双通道128bit DDR5的带宽就正好是204GB/s了。当然,从我们三易生活的经验来看,要想让这么高频率的内存稳定运行,不光CPU要支持、主板的用料也不能差,所以204GB/s的超高内存带宽,可能得花不少钱才能体验到了。
大核具备“逆超线程”黑 科技 ,小核性能不输6代酷睿
最后,我们来简单讲一下12代酷睿的内部架构设计。由于这部分的信息量实在太大,所以我们只会选择最重要的部分进行简单分析。
首先,是12代酷睿这一次的大核心架构代号为“Golden Cove”。其实从名称上也能看出,它与11代桌面版的“Cypress Cove”、10代移动版的“Sunny Cove”是一脉相承的。话虽如此,但它本身其实比前两代的变化都要大得多。
比如说,12代酷睿的大核心,首次在x86处理器上实现了6宽度的解码器设计,这意味着它的指令解码能力理论上比之前所有的x86处理器都提升了50%之多。并且与之配合的,则是它的指令缓存、微操作缓存的吞吐量都几乎翻了一番。而为了能够“喂饱”这个超大型的指令解码单元,英特尔更是直接将L2缓存的缓冲区大小从5000条增加到了12000条,同样也成为了当前已知民用级处理器中的最大规模。根据英特尔方面的说法,与前代产品相比,12代酷睿大核心的IPC性能增长了多达19%,这在行业里确实已经算是非常明显的进步了。
然而,这还不是12代酷睿大核心最“黑 科技 ”的设计。还记得我们在前文中曾提及,在12代酷睿中核心性能的优先级吗?没错,按照这一设计,12代酷睿处理器的大核心在日常的大部分时间里,可能都不会动用到超线程功能。为此,英特尔干脆在12代酷睿里弄了个特殊设计,允许大核心在不启用超线程时,将原本为超线程功能设计的、多余μOP缓存队列直接用于主线程运算,相当于是将核心的部分规格“临时加倍”。还记得2006年英特尔曾在自家主板BIOS里泄露过的“逆超线程”技术吗?在12代酷睿的大核里,它说不定真的实现了。
与此同时,12代酷睿的小核心也并不简单。要知道,它的架构其实源自于英特尔多年前的“凌动”产品线,但经过多达8代的改进和重新设计后,无论是性能还是技术指标都已经不可同日而语了。
事实上,12代酷睿的小核心有一个特别明显的特征,就是它内部的执行端口数量多达17个!要知道,它的上一代架构(Tremont)执行端口只有8个,而12代酷睿的大核心也才只不过12个执行端口。但是12代酷睿小核心的17个执行又并非17个功能不同的组件,而是包含了大量重复功能的单元。
图片来自AnandTech
这就意味着12代酷睿的小核心,从一开始就是为运算量不大、但相对重复的计算任务所设计,比如说杀毒、视频编码( 游戏 直播)、AI面部识别等等。而这也正好对应了它理想状态下的工作职能,也就是主要用于执行那些辅助性质的程序,从而让大核心可以专注于重负载的主要线程。
当然,如果你非要用12代酷睿的小核心去“办大事”,它的性能也不是不够用。事实上,按照英特尔方面公布的信息显示,12代酷睿的小核心与6代酷睿(Skylake)相比,中等功耗条件下的单核性能提升了40%;同时,12代酷睿的小核心可以仅使用约60%的功耗,就达到6代酷睿的峰值单核性能水准。
这话说的有点绕,但在经过了外媒的换算后发现,12代酷睿小核心的峰值单核性能大约是6代酷睿单核性能的108%,同时其功耗仅比6代酷睿的60%略多一点。当然,英特尔或许是顾及脸面,没有直接拿10代桌面版酷睿进行对比,毕竟10代桌面版酷睿还在售,而它的架构其实同样也是6代的Skylake。
换而言之,也就是对于12代酷睿来说,哪怕是2大核+8小核的低端型号,其总体性能也有望超过10代酷睿的10核心顶配型号。而对于8大核+8小核的顶配12代酷睿来说,性能相比10核心的酷睿i9-10900K提升80%、甚至在部分场景里提升100%,都是有可能的。
总结:12代酷睿提升不小,但它还只是剧变的前奏
总的来说,虽然英特尔目前还没有对12代酷睿的性能进行大规模宣传,但从目前已知的资料中,我们已经感受到了它此次架构改变的巨大以及性能提升的明显。
这是不是一件好事?无论对于PC行业、还是对于有志在今年年底或者明年春季换机的消费者来说,当然都是一件大好事。
反过来说,当处理器/显卡出现极大幅度的换代性能增长时,同时也意味着新的软件将会大幅提升对于硬件的需求(或者通过指令集适配,在新硬件上明显跑得更快),从而对还在使用老设备的用户造成一定的压力。
不过对于英特尔来说,12代酷睿的诞生,不仅仅意味着他们成功实现了新品竞争力的大幅提升,同时也意味着他们终于回到了产品快速更迭的轨道上来。至少,根据日前曝光的信息来看,英特尔早已规划好了从2022年到2026年的多代“大小核”处理器产品线,一边在研发全新的、可能带来30%甚至50%性能提升的下代和下下代大核架构。
另一方面,性能高功耗还低的“小核心”设计,未来也有望被进一步发扬光大。比如说可能会出现由多达64甚至128个小核心构成的服务器CPU,也可能会出现由8大核32小核组成的40核民用级新旗舰。
当然,更进一步地说,既然在12代酷睿里英特尔已经可以把“1大4小”做到5瓦的功耗水准,那么未来会不会有“2大8小”甚至“2大16小”设计的新制程处理器,再次进军智能手机等移动设备领域呢?
不得不说,12代酷睿打开了英特尔再次大幅进行技术创新的一扇大门。而这扇门里所蕴含的可能性,我们至今甚至还不能完全看透。
【本文图片来自网络】
最前线 | 英特尔换帅,技术老将帕特·基辛格接任CEO
当地时间1月13日,英特尔公司宣布,公司董事会已任命帕特·基辛格(Pat Gelsinger)为新一任首席执行官,该任命自2021年2月15日起生效。基辛格履新后也将加入英特尔公司董事会。
英特尔官方表示,CEO换任一事与英特尔2020年的财务表现无关。英特尔将于1月21日如期公布第四季度业绩和2020年全年财报信息。此外,英特尔称在7纳米制程技术方面已取得重大进展,将在1月21日的财报电话会议上更新相关信息。
此前,英特尔一直奉行技术至上主义,但现任CEO司睿博(Bob Swan)却是英特尔首个CFO出身的掌门人。2018年6月,英特尔临危受命,担任临时CEO,到2019年1月才被正式任命,在任时长仅有2年8个月。
虽然英特尔表示换帅与业绩无关,但无法否认的是,司睿博在任期间,英特尔在7nm工艺制程方面一直未能取得关键性进展。近年来,英特尔在产品发布方面一直被人诟病为“挤牙膏”,其股市表现也较为低迷。
与此同时,竞争对手AMD发展迅速,在市场份额上大举进攻;去年10月,苹果发布自研M1芯片,且宣布未来Mac将不再使用X86架构的英特尔处理器。
缓慢前行的英特尔或许痛定思痛,决心再次回归技术主流,邀请了兼具技术经验和领导能力的帕特·基辛格担任英特尔第8任CEO。
帕特·基辛格曾在英特尔工作30年,是英特尔的首位CTO(首席技术官)。他曾推动USB和Wi-Fi等关键行业技术的开发,作为80486处理器原型的架构师,他领导了14种不同微处理器的开发项目,并在酷睿和至强产品系列的成功中扮演了关键角色。
2012年,帕特·基辛格出任VMware威睿公司首席执行官,带领公司进行云基础设施、企业移动和网络安全领域的转型,使公司的年营收几乎翻了三倍。
截止发稿,英特尔股价涨6.97%。
以下为帕特·基辛格致英特尔员工的一封信:
重返英特尔担任首席执行官,我十分激动同时心怀谦卑。我18岁加入英特尔时,刚从林肯技术学院毕业。服务英特尔的30年间,我非常荣幸受教于格鲁夫、诺伊斯和摩尔门下。英特尔支持我在圣克拉拉大学和斯坦福大学继续深造。公司还让我有机会能在芯片创新的最前沿,与业界最优秀、最聪明的人才一起工作。
在英特尔的经历塑造了我的整个职业生涯,对这家公司我永远心怀感激。在这样一个推动创新的关键时期,一切都在加速数字化,我能以首席执行官的身份回到英特尔这个“大家庭”,这将是我职业生涯中最大的荣耀。
对于英特尔丰富的 历史 和所创造的强大技术,我心怀崇高的敬意,这些技术奠定了、并将继续塑造世界上的数字基础设施。我们拥有非凡的人才队伍和令人瞩目的技术专长,为业界所钦羡。
我期待着与你们所有人一起,继续塑造 科技 的未来。英特尔有着深厚的 历史 ,同时从一家CPU公司到一家多架构XPU公司的转型也非常令人兴奋;作为世界领先的半导体制造商,我们的机遇前所未有。我将于近期分享更多我对英特尔愿景、战略的思考,与此同时,我深知我们要继续加快创新步伐、夯实核心业务,为股东、客户和员工创造价值。
我要感谢司睿博在英特尔转型的关键时期发挥的领导作用和为英特尔做出的重大贡献。我欢迎他继续提供咨询和指导意见,为了我们的客户和大家,我们将尽可能确保无缝衔接。
相信大家会有很多关于下一步的问题,我期待着听到它们,即便我不会在第一天就能给出全部答案。和大家一起开启这段旅程,我已迫不及待!
